つい先日まで香港に出張しておりました。昼飯はローカルの雰囲気の漂う飲茶をいただき、それ以外の時間は香港のお客にずうううううっと技術質問攻めにあっており、疲労困憊で帰ってまいりました。なにせ、トラブル収束で行ってましたので。

で、システムトレードの方はどうかと言うと、先日一つのシステムをリストラしました。システムリストラは非常に判断が難しいのですが、有効性が無い場合、それは単なる逆噴射システムとなってパフォーマンスを押し下げてゆきます。とはいえ、システム分散も非常に重要なので、非常に悩みどころとなります。
今回切ったのは改善作業において、まったく改善に歯が立たなかったシステムです。
ただし、改善とは言っても機械学習のレベルはまだまだなのですが。
今回の改善作業
今回の改善作業はCross Validation の取り方です。
私はずぼらなので、今まで単純なHOLD OUT法で学習を実施していました。

CVを直近のTESTデータに近づけて限りなく、現状に近い所で良い成績をだせれば、TEST区間でもよい成績が残せるだろうと考えて単純に上記のようなデータの使い方をしていました。
しかしながら、思うのは必ずしもTEST区間でCV区間と同等のFactorが効きやすいことは誰も保証してくれません。もしかすると急にレジームが変化するかもしれません。
そんなこんなで思考的には全区間まんべんに学習させたい、学習したFactorがヒットする可能性を上げたいと感じるのです。そんなわけで、K-fold cross validationに変更してトライすることを考えました。
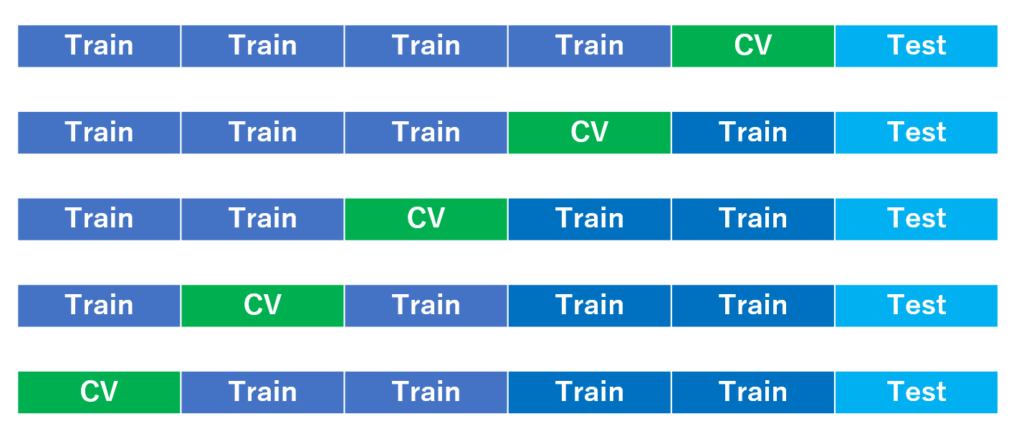
具体的にはCV区間をずらして学習してゆき、最終的には各学習モデルから出力される結果を平均して、最終出力とするもの。
コードは簡単でfor 文を応用すればできると思います。
これを実施すると、すべての区間でCVでの予測精度が出力されてきます。
K-HOLDの結果
悩める不安定なシステムに関し、特徴量は同じくして、上記区間分割にて学習を再実施し、CV区間のトレード結果を結合させて、出力してみました。
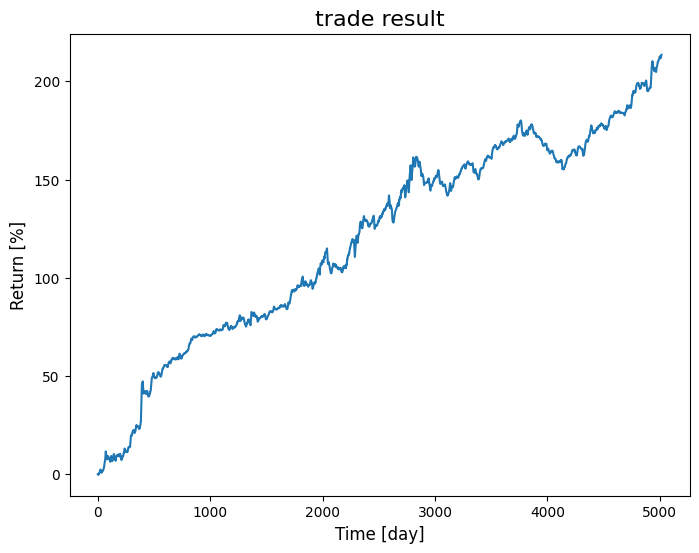
うぐ、勝率が57%ぐらい。。。これは耐えられない。
はっきり言いますと、CVを組み合わせて出た結果がこれではTEST区間や実運用区間ではもっと結果が劣後することになります。
どうしよう。。。
結論
結論としてはリストラすることにいたしました。
理想を言えば、CV区間で勝率は60%超として、実運用では58・59%ぐらいが望ましいです。
しかしながら、CVで57%であると実運用では54%から53%ぐらいが関の山なのではないでしょうか。それでは精神はもたない。崩壊あるのみ。
もうこんな辛い思いしないように、これからはちゃんとK-FOLDで検証して、満足のゆく結果を出して行きたいと思います。
なお、リストラしてから開発に着手し、新たなシステムとしてルールベースの以下のシステムを作成しております。
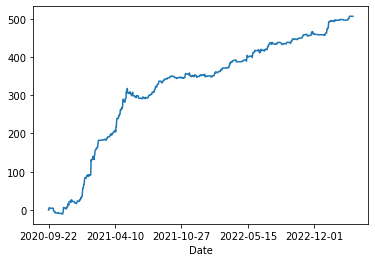
この内容に関してはまた後日に。
では。