先日、twitterにブログ記事を何か書けばよいか、tweetしたところ、
ファクターの有効性の分析手法のリクエストがありました。
そのため、今回はPythonコード付きで説明し、実際にトレード手法まで発展させていく過程を書いてゆこうと思います。
株価取得と分析フォーマット作成
まずは、Pythonで株価取得と各々のデータ結合までをやっていこうと思います。
トレードストラテジーを作ってゆくためには、データが命です。
また、プログラミングが出来ない人はこの過程を抜かしても、気合でデータ入手・加工をすればよいだけなので、他の言語・他のツールが良いという人はここは読み飛ばしてもよいです。
では、行きましょう。
#まずは準備。必要なライブラりをそろえる
import pandas as pd
import pandas_datareader.data as web #データのダウンロードライブラリPythonはExcelのアドインのように、追加でインストールできるライブラリが色々あります。
ここでは必要になるライブラリを読み込んでゆきます。
ここにあるPandasを使うと、データの統計量を表示したり、グラフ化するなど、データ分析(データサイエンス)を簡単に行うことができるようになります。
#株価の用意する。
#SPYはS&P500に連動するETF
price1 = web.DataReader("SPY","yahoo","2015/1/1").dropna()
print(price1)一番目のブロックで’web’をpandas datareader.dataとして定義しており、その構文を使えば簡単にyahoo finance @USからデータを入手できます。3行目はyahooから2015年1月1日から現在に至るまでのティッカー”SPY”のデータを入手しなさいという意味です。SPYとはS&P500に連動するETFです。
その次の行ではそれをプリントさせています。結果は以下のようになるはずです。
High Low Open Close Volume \
Date
2014-12-31 208.190002 205.389999 207.990005 205.539993 130333800.0
2015-01-02 206.880005 204.179993 206.380005 205.429993 121465900.0
2015-01-05 204.369995 201.350006 204.169998 201.720001 169632600.0
2015-01-06 202.720001 198.860001 202.089996 199.820007 209151400.0
2015-01-07 202.720001 200.880005 201.419998 202.309998 125346700.0
... ... ... ... ... ...
2021-08-02 440.929993 437.209991 440.339996 437.589996 58783300.0
2021-08-03 441.279999 436.100006 438.440002 441.149994 57987900.0
2021-08-04 441.119995 438.730011 439.779999 438.980011 46732200.0
2021-08-05 441.850006 439.880005 440.220001 441.760010 38969700.0
2021-08-06 442.940002 441.799988 442.100006 442.489990 46864100.0
Adj Close
Date
2014-12-31 181.653259
2015-01-02 181.556000
2015-01-05 178.277176
2015-01-06 176.598022
2015-01-07 178.798615
... ...
2021-08-02 437.589996
2021-08-03 441.149994
2021-08-04 438.980011
2021-08-05 441.760010
2021-08-06 442.489990
[1662 rows x 6 columns]
次にデータの加工をやってゆきましょう。
今回は終値である修正済み終値(Adj close)しか必要ありません。
このデータだけを使って、前日比を計算しましょう。
#データの中のAdj Close(終値)を用いて、前日比を求める
price2=price1.loc[:,'Adj Close'].pct_change()*100
#データ型を変換。seriesからdata frameへ
price2=pd.DataFrame(price2)
#行に名前を付ける
price2.columns=['SPY_change']
print(price2)Pythonを勉強している人はわかっていると思いますが、pandasにおけるデータ型だけはしっかりと抑えておきましょう。
処理するたびにseries型やDaraFrame型に変わってゆきますので、途中で確認しながら処理をする必要があります。
2行目にあるpct_change()は時系列データの変化率を計算する構文です。
こういうのがPythonは便利です。
このコードの結果は以下のようになります。
SPY_change Date 2014-12-31 NaN 2015-01-02 -0.053541 2015-01-05 -1.805957 2015-01-06 -0.941878 2015-01-07 1.246102 ... ... 2021-08-02 -0.209804 2021-08-03 0.813546 2021-08-04 -0.491892 2021-08-05 0.633286 2021-08-06 0.165244 [1662 rows x 1 columns]
一瞬で、S&P500の前日比データが作成できました。
つぎは日経平均のデータを加工してゆきましょう。
#日本株のデータをダウンロード。日経平均を使ってみる。
price3 = web.DataReader("^N225","yahoo","2015/1/1").dropna()#jpy
print(price3)これの実行結果は以下の通りです。
High Low Open Close \
Date
2015-01-05 17540.919922 17219.220703 17325.679688 17408.710938
2015-01-06 17111.359375 16881.730469 17101.580078 16883.189453
2015-01-07 16974.609375 16808.259766 16808.259766 16885.330078
2015-01-08 17243.710938 17016.089844 17067.400391 17167.099609
2015-01-09 17342.650391 17129.529297 17318.740234 17197.730469
... ... ... ... ...
2021-08-02 27834.599609 27493.320312 27493.320312 27781.019531
2021-08-03 27724.449219 27492.400391 27580.029297 27641.830078
2021-08-04 27636.339844 27488.740234 27612.900391 27584.080078
2021-08-05 27741.550781 27526.669922 27526.669922 27728.119141
2021-08-06 27888.869141 27709.220703 27709.220703 27820.039062
Volume Adj Close
Date
2015-01-05 116500000.0 17408.710938
2015-01-06 166000000.0 16883.189453
2015-01-07 138600000.0 16885.330078
2015-01-08 140600000.0 17167.099609
2015-01-09 155200000.0 17197.730469
... ... ...
2021-08-02 60100000.0 27781.019531
2021-08-03 57900000.0 27641.830078
2021-08-04 67500000.0 27584.080078
2021-08-05 55900000.0 27728.119141
2021-08-06 56400000.0 27820.039062
[1613 rows x 6 columns]
次にこのデータを加工します。
予測するターゲットをここで作るわけです。
ここでは日経の日中の動き、マーケットが始まってから終わるまで、寄りから引けまでのリターンを計算します。
#日本株の日中の動きを米国株の上げ下げで予想するため、openからclose(寄りから引け)までのリターンを計算する
price3=pd.DataFrame(price3)
price3=(price3['Close']-price3['Open'])/price3['Open']*100
#seriesになったデータを再度daraframeにする
price3=pd.DataFrame(price3)
#行に名前をいれる
price3.columns=['N225_change']
print(price3)3行目で計算してますね。
Pythonが良いのはここでdo文を書かずとも、列の名前の指定だけで各行のデータを計算してくれます。
そして勝手に日付と同期したデータを作成してくれる所が便利です。
結果は以下の通りになるはずです。
N225_change Date 2015-01-05 0.479238 2015-01-06 -1.277020 2015-01-07 0.458526 2015-01-08 0.584150 2015-01-09 -0.698722 ... ... 2021-08-02 1.046433 2021-08-03 0.224078 2021-08-04 -0.104373 2021-08-05 0.731833 2021-08-06 0.399933 [1613 rows x 1 columns]
次にS&P500の加工データと日経225の加工データを連結します。
注意はS&P500のデータは予測する日経225データの過去でなければなりません。
すなわちは、8月6日の日経を予測するためには8月5日以前のS&P500データでなければなりません。
下ではshift()を使って一日分データをずらしています。
#S&P500 (price2)と日経225 (price3)のリターンデータを結合する。
#ポイントはS6P500の前日のリターンで予測するのでデータは一日前にずらす。
price2=price2.shift()
#shift()だけでずらせる。便利!
conbine_price=price3.merge(price2,on='Date')
print(conbine_price)上ではmergeを使って結合してます。
基準は日付基準で、その意味で’Date’を指定しています。
結果は以下の通りです。
N225_change SPY_change Date 2015-01-05 0.479238 -0.053541 2015-01-06 -1.277020 -1.805957 2015-01-07 0.458526 -0.941878 2015-01-08 0.584150 1.246102 2015-01-09 -0.698722 1.774514 ... ... ... 2021-08-02 1.046433 -0.485643 2021-08-03 0.224078 -0.209804 2021-08-04 -0.104373 0.813546 2021-08-05 0.731833 -0.491892 2021-08-06 0.399933 0.633286 [1560 rows x 2 columns]
ここで、おまけでつけておきますが、Pythonで統計量を調べることができます。
corr()の構文で相関係数を出すことができます。
以下では相関係数を2乗した決定係数を計算しています。
conbine_corr=conbine_price.corr()**2
print(conbine_corr)結果は以下になります。
N225_change SPY_change N225_change 1.00000 0.00435 SPY_change 0.00435 1.00000
0.00435という数字を見て、どう思うでしょうか?
株の予測分析の世界では0.01を超えれば、合格ラインです。
ですので、0.01を超えるファクターを見つけるたとしたら、それは秘密にしておきましょう。
私もブログには書きません。
使っている人に迷惑ですので。
今回は0.00435という数字ですが、まぁまぁ有望ということでこのまま進めてゆきます。
つぎはCSVに落としてExcelで色々調理してゆくことにしましょう。
#最後はCSVに落として、好きに料理してゆきましょう
conbine_price.to_csv('C:/Users/*************/cobine_price.csv',encoding='utf_8_sig')*****のところは自分で好きに選んで場所を指定してください。
ここからEXCELを使う理由はその方が色々と調理しやすいと感じているだけです。
Python力が高い人はこのまま進めていっても構いません。
データ分析とトレードストラテジーへの落とし込み
ここからは分析です。
CSVファイルを開けると、下のように数字が並んでいると思います。
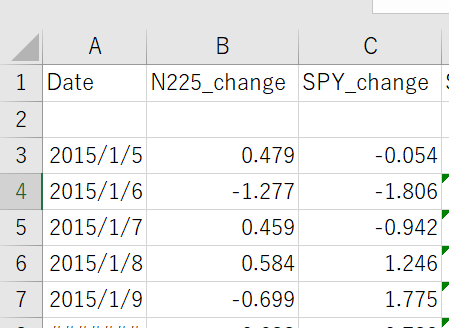
ここからは簡単でB行とC行を選び、散布図を作成します。
(もっと簡単に言うとB行をドラッグした後、CTRLを押しながらC行をドラッグし、散布図を作成します。)
その後、グラフができると、グラフ上で右クリックをして”近似曲線の追加”を押し、線形近似を選び、且つ、”グラフに数式を表示する”と”グラフにR 2乗値を追加する”にチェックを入れます。
そうすると以下のグラフが出来きるはずです。
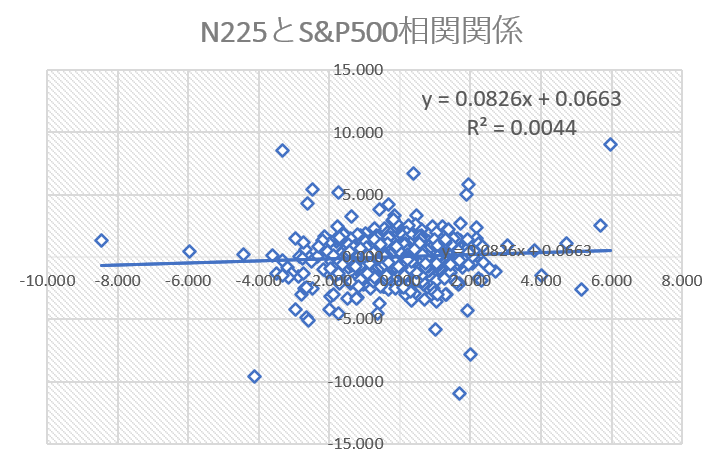
ここからわかるのは、近似曲線が右肩あがりであるためS&P500の前日比リターンは次の日の日経平均に対し正の相関を持っている事、そして決定係数は0.044(既知ですが)という事です。
つまり、
S&P500の前日比リターンが+であれば、N225を寄りで買って引けで売る、
S&P500の前日比リターンが ーであれば寄りで売って引けで買い戻せば、
というトレードで少しは稼げることを示唆しています。所謂、順張りトレードですね。
では、実際にそのようにしてトレードした結果を示しましょう。
以下の通りです。
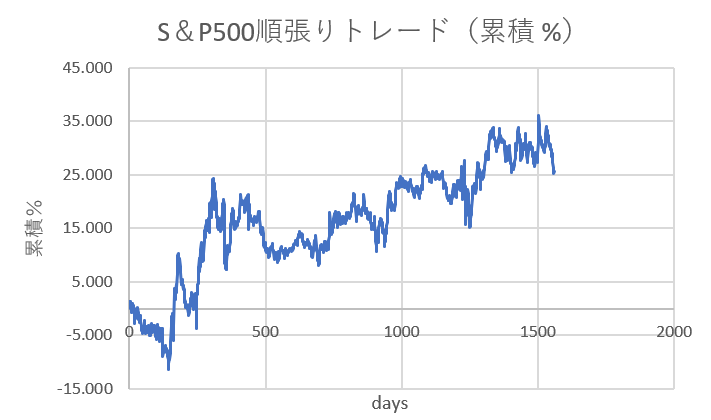
2015年から毎日1500回ほどトレードして、この結果です。
一応累積リターンは25%程度で、右肩あがりでも、このアップダウンだと精神が持たない気がします。
何とかいい方法は無いのだろうか、と思うのが普通の人です。
では、ちょっとファクターを変更し、S&P500の過去1日のリターンを使って分析していたところを少し改造を加えたものをファクターとして適用してみます。(改造内容は秘密。非常にシンプル。)
結果が下です。
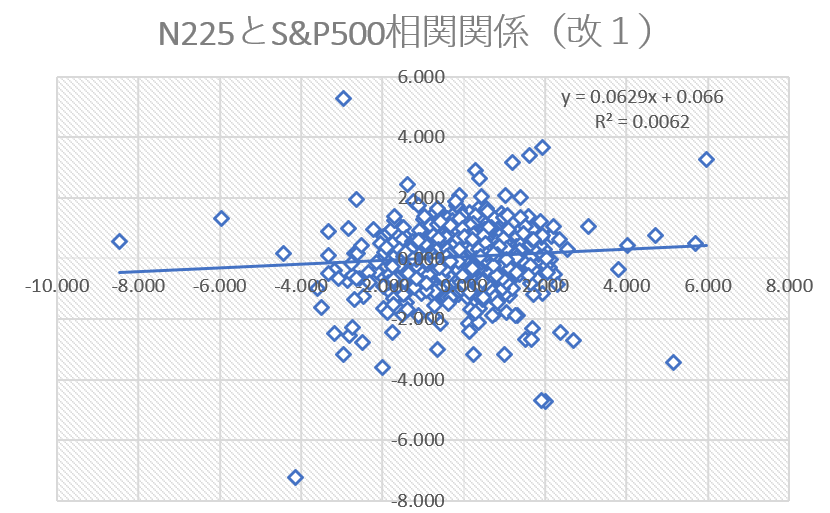
おおお、決定係数が増加して0.0062となっているではないですか。
目標の0.01に近づきました!
では、上と同様に順張りトレードを寄り・引けで実施すればどうなるでしょうか?
改善を期待してみましょう。
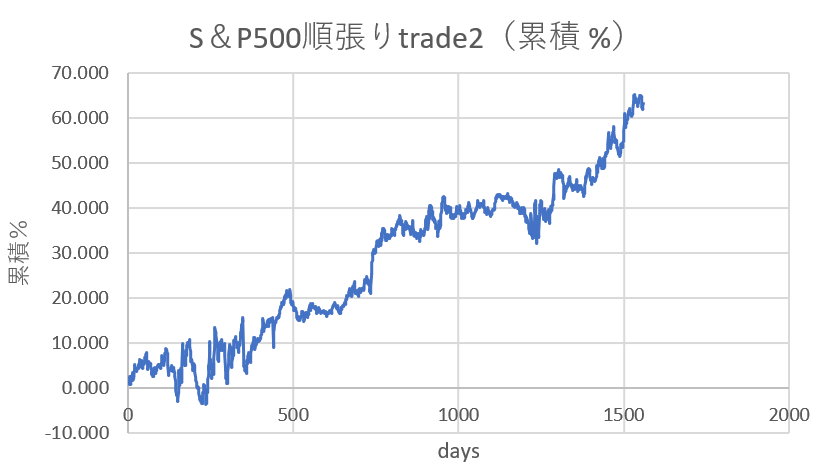
え、意外とイケる。5年半のトレードでトータル65%はちょっと控え目ですが、右肩上がりのグラフが出来ました。ここから改善策は無いのかと問われると、またもや企業機密になってきます。
ただし、本当にあるのかどうかを示すために、ちょっと老舗の味を混ぜて調理してみました。
下はある一つの条件を、上のトレード条件に加えたものです。
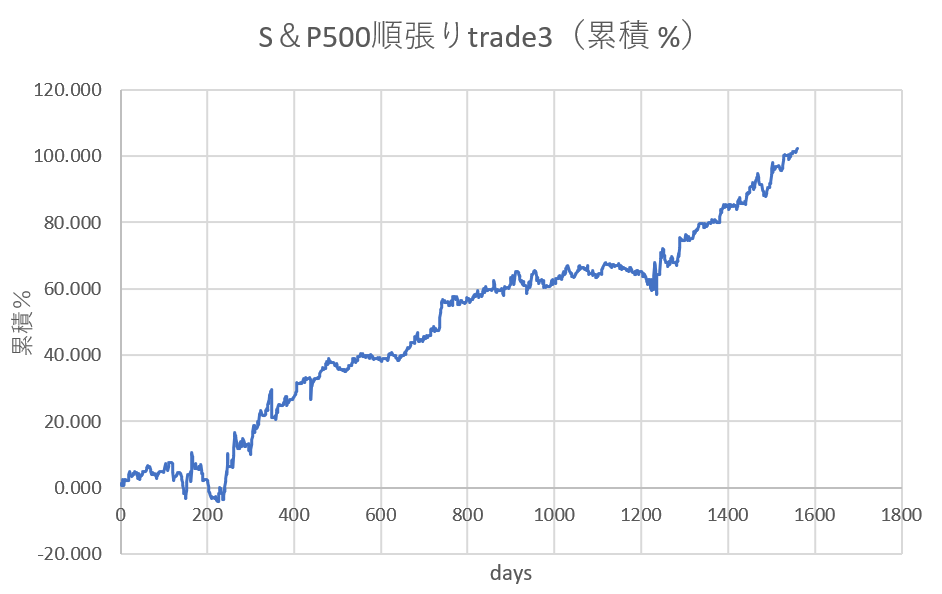
素晴らしい!リターンが1.5倍になりました。これは単利でのトレード結果なので複利で運用すれば、結構な稼ぎになります。
更に、更に、もう一つの条件を入れてトレードしてみましょう。
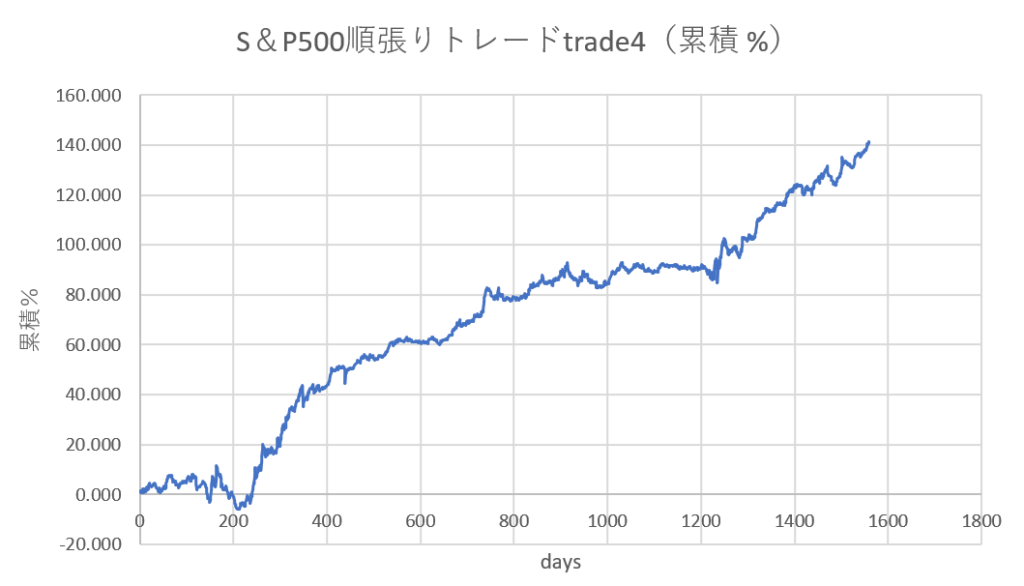
おおおお、5年半で140%も単利で稼いているでは無いですか!!!
もし日経平均先物で、レバレッジ3倍で運用、且つ複利で運用すれば…。
ただし、昔はS&Pに対し、逆張りでトレードしていれば稼げたところが、昨今では順張りになっているのです。そのため、この法則がいつまでも続くという保証はありませんので、実弾を投入するには躊躇する次第です。
でも、今回言いたいことは、株価の分析は簡単にでき、更には過去データに基づいて分析すれば簡単にその有効性を調べることができます。そして、有効なファクターを幾つか組み合わせて機械学習をすれば、更に有効なトレード手法が見つかるかもしれません。更に更に付け加えると、ファクターは別にテクニカル系の計算値でも構わないわけです。それが有効であれば、秘密で使ってゆきましょう。
過去のデータと未来のデータに相関関係があれば、それは利益の源泉です。
今回は日足データを使いましたが、別に分足でも月足でもよいし、データも質的データを数値化したものでもよいし、なんでも良い訳です。S&Pの代わりにAPPLEの株価を使っても良いのです。有効であれば。
参考事例に囚われず、どんどん視点を変えて分析していってもらえれば、と思います。